
I-JEPA [1], the latest self-supervised model from Meta AI, has been officially released: the paper was published in June 2023 at the last CVPR conference, together with their codes that they made open-source.
This new architecture falls in the continuity of Yann Lecun vision for more human-like Artificial Intelligence.
Self-supervised learning (SSL) is a field of machine learning where a system learns to capture relationships between inputs, without the need of any label. It means that the system will not learn directly to predict a specific label, but more high-level information. In computer vision, there are two main approaches for SSL: invariance-based methods and generative methods.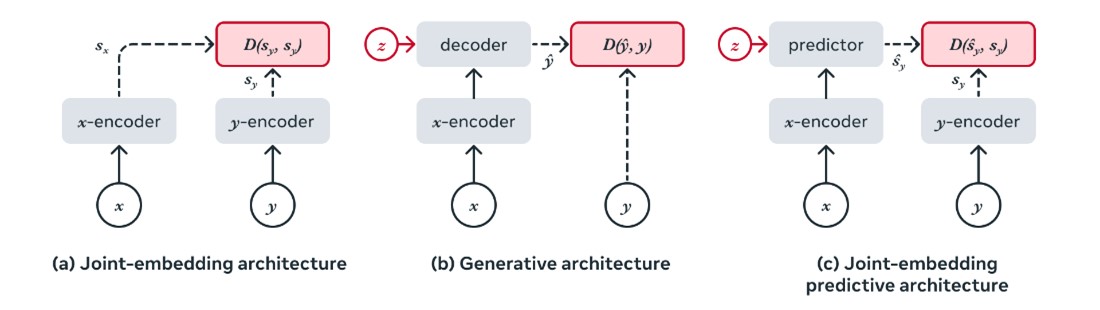 The invariant-based methods (also called joint-embedding methods) aim to output similar vectors for a set of views of the same image. This set of views can be created by applying different data augmentations to an image for example. The main characteristics of such architecture is the encoder, which will encode the images into a latent space, and a contrastive loss that will ensure the model learns to attract similar embeddings, and repel dissimilar embeddings.
The invariant-based methods (also called joint-embedding methods) aim to output similar vectors for a set of views of the same image. This set of views can be created by applying different data augmentations to an image for example. The main characteristics of such architecture is the encoder, which will encode the images into a latent space, and a contrastive loss that will ensure the model learns to attract similar embeddings, and repel dissimilar embeddings.
The generative methods aim to reconstruct an image or part of an image from using a decoder network that is conditioned on an additional variable z, mainly in the latent space, to facilitate the reconstruction. A possible approach for images is to mask a part of an input image and the model tries to reconstruct the missing part. In this case, the additional information z corresponds to a position token that specifies to the decoder part of the image to reconstruct.

I-JEPA overview
I-JEPA is a novel generative method, where the model learns to reconstruct the masked patch of an input image, but instead of a pixel-by-pixel reconstruction, the authors introduced a representation reconstruction, directly in the latent space. From an original image, we define :
- a context block, representing the image with missing patches. This will be the given as input of the I-JEPA model.
- the target blocks that are the the missing patches that we want to reconstruct.
Compared to generative methods that predict in the pixel space, the prediction of target embeddings allows to only keep the semantic and useful information, and potentially eliminate unnecessary details contained in the pixels.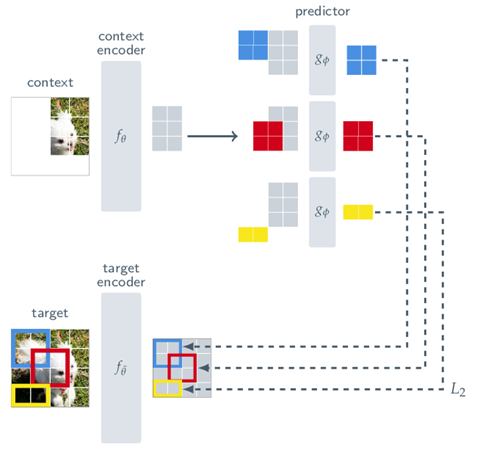
Architecture
The architecture of the I-JEPA model is simple. It is composed of a context encoder and a target encoder with the same architecture, and a predictor. The inputs of the two encoders are images and their output is a embedding vector representing the image. The predictor will take the embedding vector representing the context image as the input, and will output another vector representing the missing target block. I-JEPA will then learn to predict representation vectors as close as possible (L2-distance) to the encoded target block. In the paper, the authors use Vision transformer [2] for the encoders and predictor.
Visualization of the predictions
In order to understand what the model is capturing, the authors also trained a generator that maps the predicted vectors into the image space. This qualitative evaluation allows to visualize how the model’s output can help to reconstruct the missing patches. The below image shows some examples of reconstructed blocks given the predicted representation vector.

Results
In terms of quantitative performance, the authors compared I-JEPA to other self-supervised methods for classical computer vision benchmarks: fully supervised image classification, few-shot image classification, object counting, and depth prediction. This comparison spotlights the computational efficiency and accuracy of this new model, by predicting directly in the representation space. In the below graph, we observe the accuracy on Image-Net dataset as a function of the pretraining GPU hours.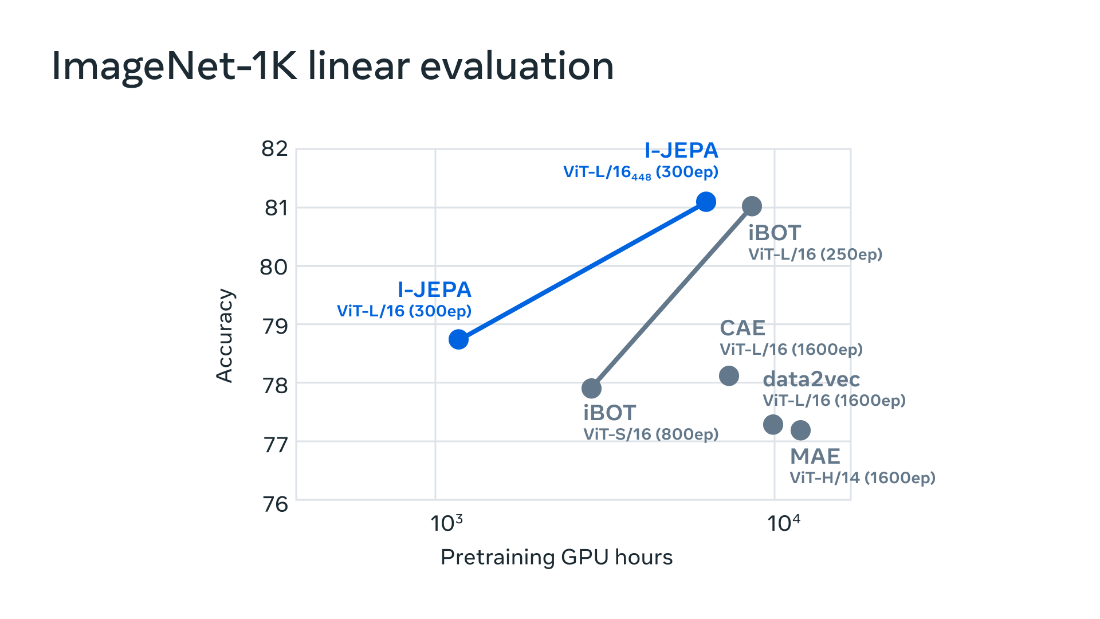 Conclusion
Conclusion
To conclude, I-JEPA has several advantages:
- it learns to reconstruct hidden parts of an image.
- it is simple and efficient for learning highly semantic representations.
- for a same level of accuracy, I-JEPA is 10 times faster than other methods in terms of pretraining.
- for a same pretraining time, I-JEPA shows higher accuracy than the other methods.
- it has the ability to generalize to different computer vision tasks.
- it brings self-supervised learning one step closer to human-level intelligence.
References
[1] Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas. Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture. arXiv preprint arXiv:2301.08243, 2023
[2] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020