
If today privacy is mainly discussed in the contexts of maintaining databases and leaks from them, in the near future it will grab headlines and the attention of companies even when it comes to learning and training the machine. The arcile is writen in Hebrew.
אם כיום הפרטיות נדונה בעיקר בהקשרים של שמירה על מאגרי מידע ודליפות מהם, בעתיד הקרוב היא תתפוס כותרות ואת תשומת לב החברות גם כשזה נוגע ללימוד ולאימון המכונה ● אביגיל גולדשטיין, חוקרת בתחום ביבמ, מסבירה
פרטיות היא מונח שמתקשר בדרך כלל למאגרי מידע ולדליפה של נתונים מהם. אלא שיש לנושא הזה עוד הרבה אספקטים, גם בתוך המובן הטכנולוגי והאינטרנטי שלו. אחד מהם, שלא כל כך דובר בו עד עכשיו – בכל אופן הרבה פחות מאספקטים אחרים – הוא לימוד המכונה. עד כמה נשמרת הפרטיות בתהליכי הלימוד והאימון של המכונה? מהן המתקפות על המודלים בעולם זה? ואיך ניתן להגן מפניהן?
בשאלות האלה עוסקים כבר לא מעט זמן במעבדות המחקר של יבמ בחיפה, בשיתוף עם מעבדות אחרות של החברה, בעיקר בארצות הברית ובדבלין, אירלנד. אביגיל גולדשטיין היא אחת החוקרות הבולטות בתחום במעבדות הצפוניות של הענק הכחול, ובכלל בכל הנוגע להגנה על כלי בינה מלאכותית. היא הגיעה ליבמ לפני יותר מ-14 שנים, אחרי שעבדה באינטל בתור סטודנטית. כל הזמן הזה היא מהווה חלק מקבוצת אבטחת המידע והפרטיות במעבדות המחקר של יבמ, ועוסקת בפרויקטים שעוסקים בפרטיות ובהגנה על המידע.
"הפרויקט הנוכחי שלי מסתכל על אספקטים שקשורים לפרטיות בהקשר של מודלים של לימודי מכונה. ספציפית, אנחנו בין השאר שותפים לפרויקט אירופי שעוסק בגילוי מוקדם של מלנומה, ועוזרים לייצר מודלים ששומרים על פרטיות המידע של החולים", אמרה גולדשטיין לאנשים ומחשבים. "אם עד לפני כמה שנים עסקו בפרטיות המידע סביב המידע והרשומות, התחילה בשנים האחרונות להיות הבנה שצריך להתייחס אליה גם אחרי שמעבדים את הדטה ומאמנים עליו מודל של לימוד מכונה, כי יש בתוך המודל הזה מידע על הנתונים ששימשו לאימון שלה, שיכול לדלוף. לפני כמה שנים התחילה ביבמ ובמקומות נוספים הבנה שלא מספיק להגן רק על הדטה, צריך גם להבין איזו מידת סיכון קיימת ואיך לבצע את ההגנה על פי הרגולציות הרלוונטיות, למשל ה-GDPR של האיחוד האירופי".
אילו מתקפות הן הנפוצות ביותר על מודלים של אימון מכונה?
"אחת מהן היא Membership Inference Attack – התקפת שייכות. התוקף מנסה להבין האם רשומה מסוימת הייתה חלק מאימון של מעגל מסוים. לפעמים הידיעה האם הבן אדם שהרשומה מכילה את פרטיו השתתף באימון מסגירה עליו מידע. למשל, אם הפרטים עליו מצויים במודל שמאמן את המכונה בכל הנוגע לאישור הלוואות, אפשר להסיק שהוא לקוח של אותו הבנק. אם המודל הזה מופעל בבית חולים, אפשר להסיק שהוא טופל שם ושיש לו בעיה רפואית כלשהו. עם המידע הזה הוא יכול לסחוט את אותו אדם או ארגון, או למכור אותו.
מתקפה נוספת היא Attribute Inference Attack, שמאפשרת גילויים וגם שחזורים בעזרת המודל. לדוגמה, אם התוקף רוצה לזהות פנים, המתקפה הזו יכולה לעשות זאת, במידה מסוימת, על ידי שחזור מתוך המודל. זה אף פעם לא 100% מדויק, אבל הוא יכול להבין במי מדובר. כנ"ל לגבי שחזור טקסטים".
מה אתם עושים בפרויקט?
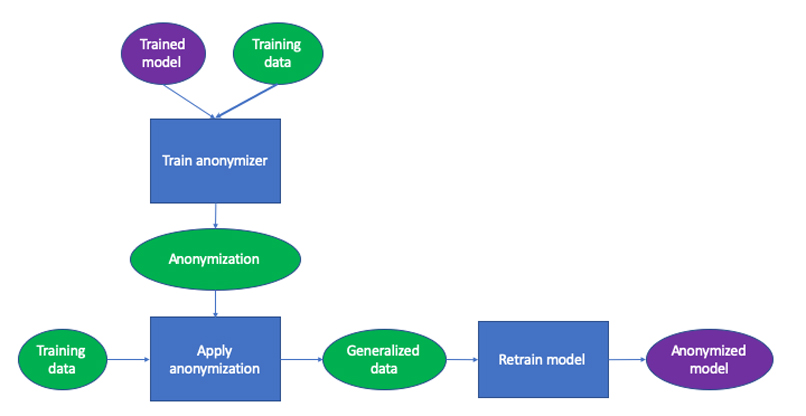
"שני דברים: הערכה של מידת הסיכון לפרטיות שמהווה מודל מסוים ופיתוח טכנולוגיות הגנה. אנחנו מבצעים את ההערכה בין היתר על ידי כך שאנחנו מריצים מתקפות על המודל ומנסים להבין כמה מידע מודלף או יכול להיות מודלף ממנו. אנחנו מנסים לאמוד את זה ולתת תמונת מצב מה רמת הסיכון של המודל מבחינת פרטיות המידע. בנוסף, אנחנו מפתחים טכנולוגיות שמאפשרות להקטין את דליפת המידע לאחר המתקפות, לנטרל את המתקפות האלה ולענות לסעיפים ספציפיים ברגולציה, כמו מינימיזציה של דטה או הזכות להישכח, שעד עכשיו לא טופלו כמו שצריך בעולמות המודלים".
לאסוף כמה שפחות נתונים ולשמור כמה שיותר על הדיוק – זה אפשרי?
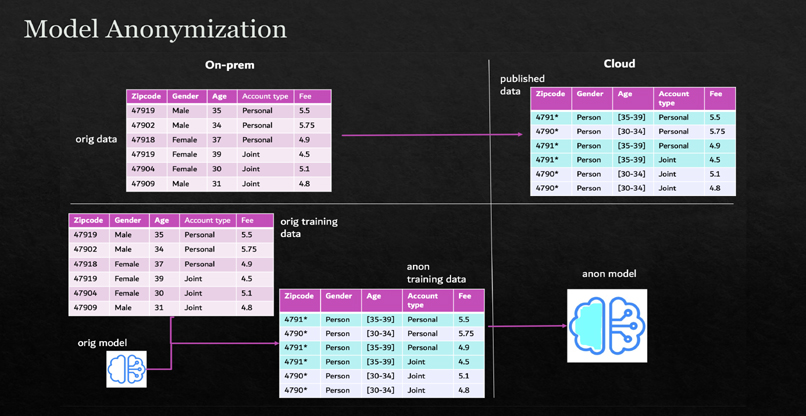
לדברי גולדשטיין, "לכאורה, אחת הדרכים הטובות ביותר להגן על הפרטיות היא לאסוף כמה שפחות נתונים. אלא שזה פוגע ברמת הדיוק של ניתוח המידע ובאימון המכונה. מאוד קשה למצוא את מה שיאזן בין השניים. אנחנו מנסים לקחת שיטות קלאסיות של אימון ולימוד מכונה, ולהתאים אותן כך שיעבדו בצורה שמונחית על ידי המודל. כמו כן, אנחנו יוצרים אנונימיזציה שמותאמת למודל הספציפי. עדיין יש צורך לטשטש את המידע, כדי לשמור על הפרטיות ולהתאים לרגולציה, אבל כך ניתן לעשות זאת במקומות שהמודל פחות צריך את המידע שיש בהם".
מה דעתך באופן כללי על מה שקורה בסוגיות שונות שקשורות לשמירה על הפרטיות?
"בכמה השנים האחרונות הייתה התפתחות משמעותית במודעות ובהתייחסות של חברות לפרטיות. מאוד תרמו לזה תקנות ה-GDPR. עד אז הן די התעלמו מנושא הפרטיות, ועכשיו הן נאלצות בעל כורחן לקחת את זה יותר ברצינות, בגלל המודעות הגוברת בציבור והרגולציה.
באשר לפרטיות בלימוד ובאימון המכונה – זהו נושא שעדיין נמצא בהתהוות. דנים על זה באקדמיה כבר כמה שנים, ובשנים הקרובות זה יהפוך להיות מיינסטרים גם בתעשייה, כמו שפרטיות המידע הפכה להיות מיינסטרים זה מכבר. גם כאן הנושא ייכנס למיינסטרים בגלל הרגולציה.
כיוון נוסף, שגם במחקר שלו אנחנו עוסקים הוא הזכות להישכח. הכוונה היא ללקיחת מודל שאמון על כמות גדולה של מידע ומחיקת אנשים ספציפיים בלי להצטרך לאמן את המכונה מחדש. זה קשה במודלים גדולים ומסובכים, עוד לא פתרו את הבעיה הזאת".
Article published at https://www.pc.co.il/news/352603/