
The iToBoS project has multiple data flows supporting different types of sharing/exporting of data, both between partners and with external entities. As part of this process, on some of the data, the project will employ masking.
Specifically, the iToBoS project is planned to make use of Magen, the next generation data masking engine from IBM Research. In this short article we present a high-level overview of Magen’s architecture, more details can be found in [1].
At a very high level, the process of masking is composed of the following four parts:
- Read and parse the data (e.g., xml, csv etc.).
- Select and classify the relevant (e.g., sensitive) elements.
- Modify the element(s) (e.g., redact, tokenize, etc.).
- Update the data and write the modified payload (maintaining the payload structure).
Magen’s architecture is composed of three main components, each addresses different parts of the masking process:
- Core – responsible for the masking engine API and policy, for parsing the payloads, conditional execution and selecting the relevant items.
- Metal – a library that is responsible for providing all the advanced encryption and tokenization functionalities including format preserving encryption and tokenization.
- Format - providing the user basic blocks and tools to create her/his own formats. Each format is responsible for implementing the operations search, match as well as rank a string to integer and vice versa (unrank). This ranking and unranking is an integral part of the masking process to support format preserving encryption and tokenization.
Next, we provide a high-level description of each of those components.
Core
Magen’s Core component provides the main API for masking. The following code snippet shows how a Masking engine can be created and executed:
Magen magen = new Magen(policy)
String masked = (String) magen.process(payload, metadata, state)
The first line creates a masking engine based on a policy. Once the engine is instantiated, it can process payloads. The second line shows a call to process. Process has 3 arguments, the first is the payload (e.g., an XML, Json or string), the second is the metadata which holds keys and values supporting conditional execution (e.g., to decide whether to encrypt or decrypt) and the last parameter, state, is used to provide the encryption key and iv.
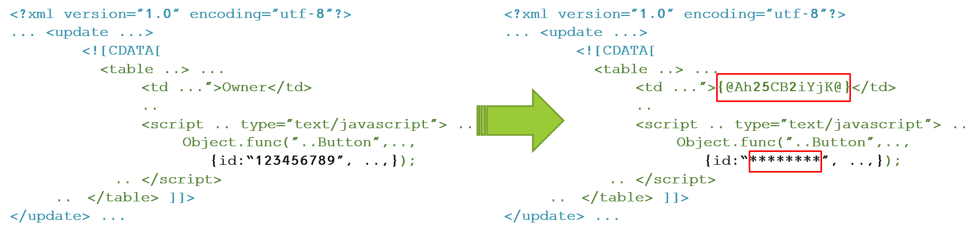
The policy is a json file used to configure the engine. The engine is a graph-based data flow which allows us to handle separately different aspects of the processing flow. For example, using the policy a user can specify how a composite payload, such as a Json within a CSV column, should be parsed and decomposed. Moreover, the user can guide the engine during the decomposition process, and provide instructions to identify and/or select different elements, such as the relevant column/row in the CSV, or the JsonPath where the target element is located. Lastly, the user specifies and configures the specific masking method (e.g., redact, tokenize, encrypt) to apply on each element. Once the elements have been masked, the engine composes the payload back by using the same flow in a reverse manner.
Metal
Metal is the component able to apply different types of cryptographic transformations. Several of these transformations are highlighted in the following table:
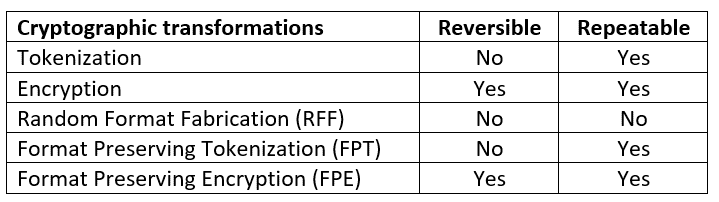
Metal supports two types of encryptions: standard encryption (AES) and Format Preserving Encryption (FPE), where, for example, a phone number 617-628-2047 is encrypted to another phone number in the domain, such as 201-289-1443. Both types of encryptions are, as expected, reversible and repeatable, meaning the same input value is always encrypted to the same output value.
In addition to encryption, Metal supports three types of tokenization: the first, tokenization, simply replaces a value with a token based on a hashing function (SHA3-256). The second, Format Preserving Tokenization (FPT), replaces a value with a token of the same format (e.g., an email This email address is being protected from spambots. You need JavaScript enabled to view it. will be tokenized to another email in the domain such as This email address is being protected from spambots. You need JavaScript enabled to view it.). Format Preserving Tokenization is based on a hashing function internally and as such, both of these types of tokenization are irreversible and repeatable. Lastly, Random Format Fabrication is a tokenization method built upon Format Preserving Tokenization that provides a random IV on each invocation. This means that tokenization is irreversible but also not repeatable, meaning two invocations of Random Format Fabrication on the same value will yield two different results.
Format
Format is the library responsible for defining formats or data types such as Social Security Number (SSN), phone number, email, credit card number (CCN), etc. Format provides a flexible API allowing the user to construct formats hierarchically (without limitations), using for example concatenation or union of other formats. The library also provides a set of configurable basic formats which can be used by the user as building blocks, such as integer range, string set, regular expression, fixed length integer, etc. Lastly, Magen has a large set of predefined formats covering many of the known data types.
Each format is required to realize three methods: search, match and rank. Search and match are used for searching and matching values in free text while rank is used by Metal when applying the rank and cipher approach [2].
IBM Research, Micha Moffie.
Bibliography
[1] M. Moffie, D. Mor, S. Asaf and A. Farkash, "Next Generation Data Masking Engine," in Data Privacy Management, Cryptocurrencies and Blockchain Technology, 2022.
[2] M. Weiss, B. Rozenberg and M. Barham, "Practical Solutions For Format-Preserving Encryption," in Web 2.0 Security & Privacy, 2015.