
As the use of AI becomes increasingly pervasive in business, machine learning models are one of the ways industries can best make the most of existing data to improve business outcomes.
But such ML models have a distinct drawback – they traditionally need huge amounts of data to make accurate forecasts. That data often includes personal information, the use of which is governed by data privacy regulations and guidelines, such as the EU’s General Data Protection Regulation (GDPR). GDPR sets a specific requirement called data minimization, which means that organizations can collect only the data they really need.
And it’s not only data privacy regulations that need to be considered when using AI in business. Collecting personal data for machine learning analysis also represents a big security risk when it comes to data breaches, as well as high storage and operational costs.
To continue to benefit from the advantages of machine learning, while minimizing the collected data, IBM has a new open source technology that can be used to determine what data is really needed by an ML model (https://youtu.be/BVdSxIesDHg). Given a trained machine learning model, IBM’s toolkit can determine the specific set of features, and the level of detail for each feature, that are needed for the model to make accurate predictions on runtime data.
Determining the minimal amount of data required, especially in complex machine learning models such as deep neural networks, can often be difficult. We developed a first-of-a-kind method that reduces the amount of personal data needed to perform predictions with a machine learning model by removing or generalizing some of the input features of the runtime data. Our method makes use of the knowledge encoded within the model to produce a generalization that has little to no impact on its accuracy. In some cases, less data can be collected while preserving the exact same level of model accuracy as before. But even if this is not the case, in order to adhere to the data minimization requirement, companies are still required to demonstrate that all data collected is needed by the model for accurate analysis.
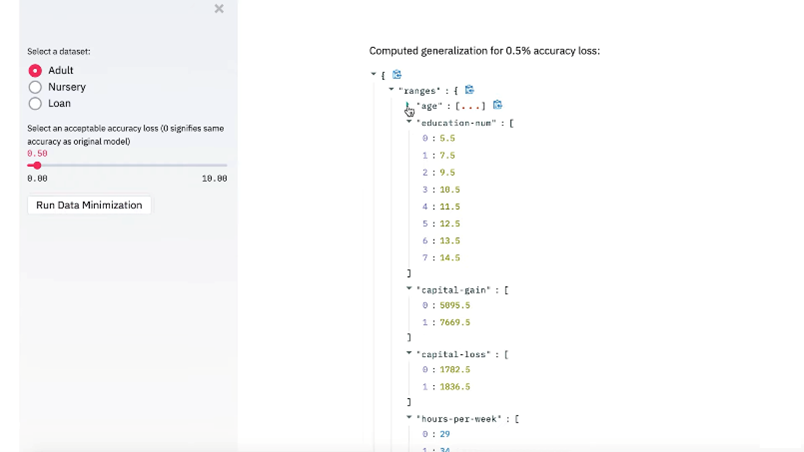
IBM AI minimization tool
This technology can be applied in a wide variety of industries that use personal data for forecasts, but perhaps the most obvious domain is healthcare. Let’s say research scientists are developing a model to predict if a given patient is likely to develop melanoma, so that advance preventative measures and initial treatment efforts can be administered.
To begin this process, the hospital system would generally initiate a study and enlist a cohort of patients who agree to have their medical data used for this research. But they don’t want to collect and store more sensitive medical, genetic, or demographic information than they really need.

Using IBM’s minimization tool, the hospital can decide what percent reduction in accuracy they can sustain, which can be very small or even none at all. The IBM tool can then automatically determine the range of data for each feature, or even show that some features aren’t needed at all, while still maintaining the model’s desired accuracy.
We recently published an initial proof-of-concept implementation of the data minimization principle for ML models. We also published a paper where we presented some promising results on a few publicly available datasets. Download the toolkit and try it for yourself.
Abigail Goldsteen, IBM Research.