
I recently took part in MIE conference in Nice, France. This year the conference focus was on “challenges of trustable AI and added value on Health”.
MIE is a conference that concentrates on the benefits of medical informatics to healthcare. The dramatic increase in machine learning in healthcare gave more and more focus to AI applications and their benefits in the recent years. The fact that the focus of MIE this year was on Trustable AI demonstrates that security and privacy in AI, specifically in healthcare, is becoming a necessary piece in the puzzle for hospitals and healthcare organizations. This gave us an opportunity to present our work on Privacy in AI that we are extending in the iToBoS project (https://pubmed.ncbi.nlm.nih.gov/35612030/).

There is a known tension between the need to analyze personal data to drive business and privacy concerns. Many data protection regulations, including the EU General Data Protection Regulation (GDPR) and the California Consumer Protection Act (CCPA), set out strict restrictions and obligations on companies that collect or process personal data. Moreover, machine learning models themselves can be used to derive personal information, as demonstrated by recent membership and attribute inference attacks.
In MIE we presented two privacy measures to protect privacy in different phases of the AI lifecycle: Model Anonymization and Data Minimization, and demonstrated how they can be used in a real life medical system (like the iToBoS system).
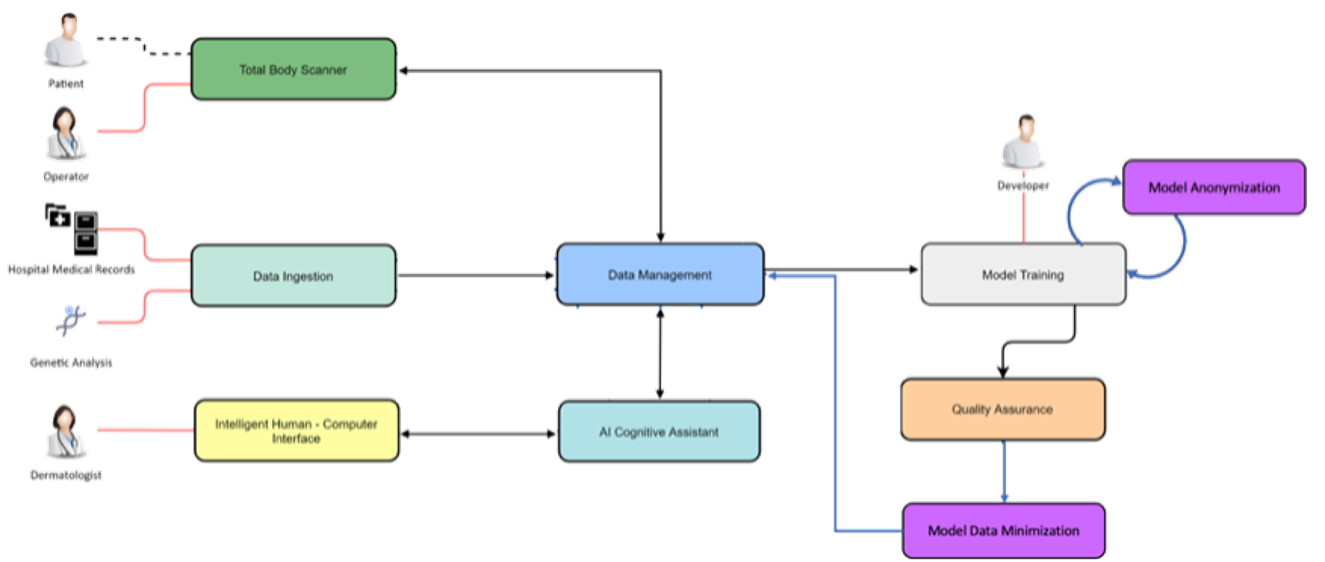
Model Anonymization – Since anonymous data is exempt from data protection principles and obligations. We wanted to re-build organizational models based on anonymized data. However, learning on anonymized data typically results in a significant degradation in accuracy. We addressed this challenge by guiding our anonymization using the knowledge encoded within the model and targeting it to minimize the impact on the model's accuracy, a process we call accuracy-guided anonymization.
Data Minimization – GDPR mandates the principle of data minimization, which requires that only data necessary to fulfill a certain purpose be collected. However, it can often be difficult to determine the minimal amount of data required, especially in complex machine learning models such as neural networks. We presented a method to reduce the amount of personal data needed to perform predictions with a machine learning model, by removing or generalizing some of the input features. Our method makes use of the knowledge encoded within the model to produce a generalization that has little to no impact on its accuracy.
For a conference that is healthcare and health informatics oriented, I was surprised to see how much interest there was in this work, with many people approaching me and describing in length the hurdles they have hit in their work and research due to privacy concerns and the relative lack of tooling that is both usable and enables reasonable accuracy.
Ariel Farkash, IBM.