
Object detection methods have been developed since early 2000s and continue to grow rapidly until now. The history of object detection can be separated into two eras: traditional detection methods and deep learning based detection methods.
From early 2000s until 2012 is the era of traditional detection methods, with the well known names such as: Viola–Jones and Histogram of Oriented Gradients (HOG). These methods often rely on extracting handcrafted features like edges, corners, gradients from images, therefore, have several limits. For example, Viola–Jones can detect well frontal human faces but fail on sideways and up/down faces.
In 2012, AlexNet, a deep Convolutional Neural Network (CNN) architecture, was born and immediately achieved a considerable accuracy on the ImageNet LSVRC-2012 challenge. This event opened up a new era for the development of object detection methods. Since then, object detection has started to evolve dramatically.
Figure 1 summarizes the evolution of object detection methods. As can be seen, deep learning based object detection methods can be separated into two categories: one stage detectors and two-stage detectors.
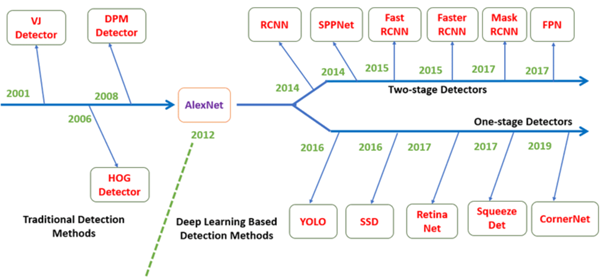
Fig. 1. Object detection milestones (source)
One-stage vs two-stage object detector
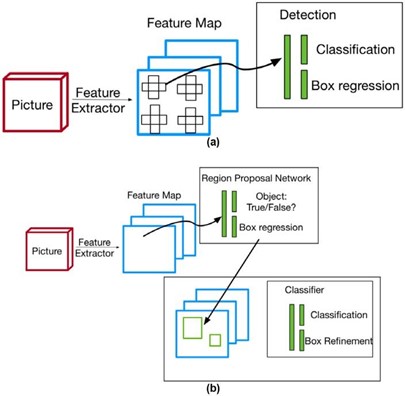
Fig. 2. Comparison of one-stage (a) and two-stage (b) object detectors (source)
Object detection, by its nature, is a two stages process: identification of objects, then finding object location in images. Two-stage detectors have been developed by reflecting this approach. As can be seen in Fig2 (b), two-stage detectors firstly go through a Region Proposal Network to identify potential regions that contain objects. Then these regions are further examined in the second stage to predict the category and the bounding box for each object. Typical two-stage detectors include RCNN family in which Faster-RCNN and Mask-RCNN are some of the most popular two-stage detectors.
One-stage detectors, on the contrary, treat object detection as a simple regression problem. Input image is fed to the network and the detector directly return the prediction of category and bounding box of each object. In other words, one-stage detectors skip the Region Proposal stage and go directly to detection head. Typical one-stage detectors include YOLO family, Single Shot Detector (SSD) and RetinaNet.
While two-stage detectors are considered more accurate than one-stage detectors, they are often slower due to multiple stages. However, the gap of performance between the two categories has been significantly reduced with many break-through Deep Learning technologies. Recent one-stage detectors, such as YOLOv7, are beating two-stage detectors, like Mask-RCNN, in term of speed and performance.