The data obtained in the University of Queensland (UQ) will follow a specific data flow that will differ slightly on the one followed by the Clínic Hospital in Barcelona.
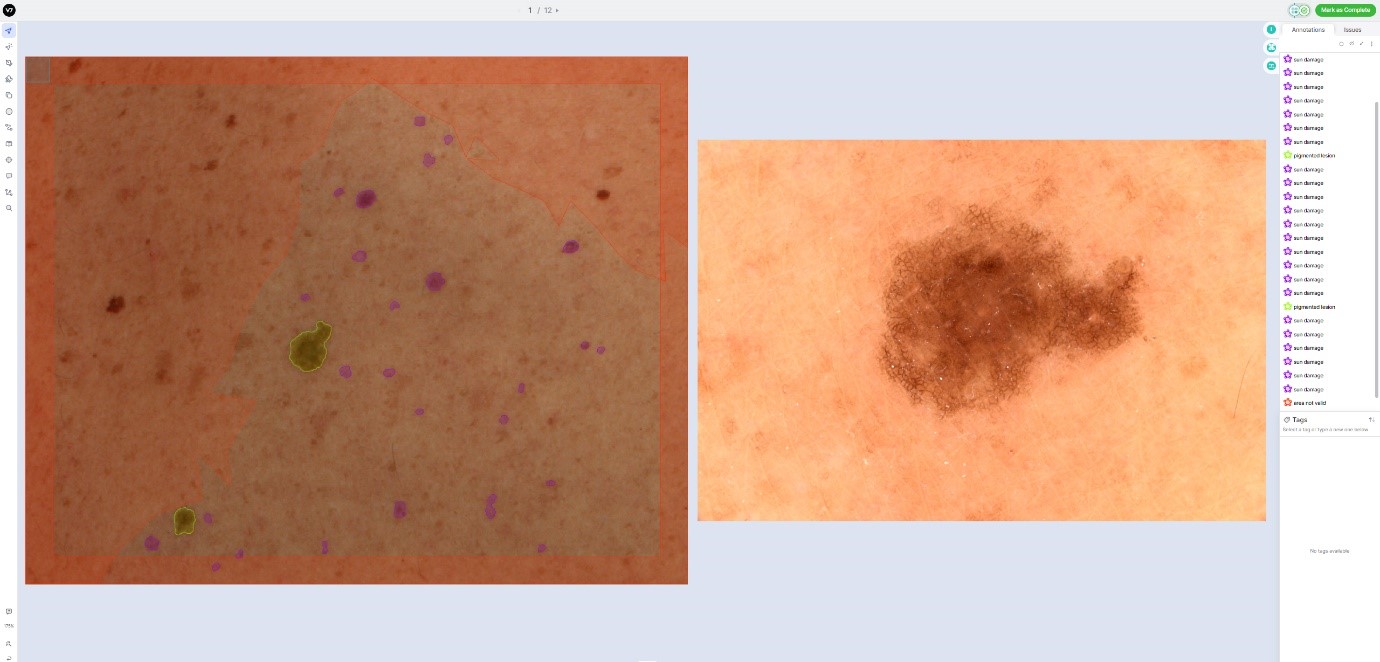
The first steps will be the same, capturing 92 images for each patient using the VECTRA scanner, and using the VECTRA’s software to create a 3D reconstruction of the patient’s skin. When the physicians scan a patient, they will also add to the patient data several manually obtained dermoscopic images of the most suspicious lesions, in order to facilitate their classification in the following steps. Those images will then directly be processed by Canfield in order to anonymize them, removing the head of the patient and dividing them into smaller tiles. Similarly, as in the process followed in the Clínic Hospital, an AI system will provide with lesion predictions and the images will be converted into the DICOM format, merging images and masks together in a multiframe DICOM file.
The data will then be uploaded to the cloud, which will be accessed by the annotators that will again delete false positives and correct the predicted annotations to have a better-quality ground truth. They will also need to highlight differently the lesions of interest, as they appear larger than 3 mm diameter and with high pigmentation.
Once the annotating force finishes processing the images, the new annotations can be exported back to the iToBoS Cloud. At this stage, the images will be analyzed by physicians from the University of Trieste, who will need to classify all the lesions of interest into suspicious/non suspicious. The doctors will also have, for each tile, access to some of the dermoscopic images of the lesions that may appear in the tile, when they exist, so that they can perform a better evaluation of the lesion.
At that point, the data will be uploaded back to the iToBoS Cloud, and the new cleaned and classified annotations will be sent back to Canfield to refine the AI predicting system. In this way, the data will be ready to be used to train diagnosis assistant tools, completely anonymized and with a reliable ground truth.