
In September 2022 (M18 of the project) we submitted deliverable D4.1 - Masking and anonymization tools for datasets. We bring here some highlights from that deliverable.
This deliverable focused on the tools for preserving the privacy of tabular datasets as well as DICOM metadata (headers). It mainly covered the data masking tool for data privacy, describing the tool, its capabilities, the requirements gathered so far from the consortium regarding the expected application of the tool in the project, and the adaptations and new features that have been developed so far based on those requirements. As the privacy requirements of the project have not been completely finalized to date and may continue to evolve over the different phases of the project, changes may be made to the assumptions and requirements as well as to the use of the tool later on in the project.
In previous articles we briefly described the masking tool’s capabilities and its proposed use in the iToBoS project. Here we will go into more details about how these goals were achieved.
The iToBoS project deals with a variety of patient personal data, including demographic, clinical and genomic data, imaging data and family history. The data in the iToBoS cloud will be stored in two main formats: csv files for the tabular data, and DICOM files for the imaging data[1]. The DICOM format also supports attaching to each image a set of metadata headers, that includes information that is specific to the image but may also include different attributes of the patient, study, site, etc.[2] Finally, towards the end of the project, a sub-set of data stored in the iToBoS cloud is planned to be released publicly as part of two open iToBoS challenges.
In order to preserve patients’ privacy and prevent re-identification of specific patients, we plan to employ IBM’s data masking tool.
As mentioned in Advanced masking technologies in the iToBoS project, the masking tool will be used to mask patient identifiers, as well as visit dates and other dates and times present in both tabular and DICOM data. As both IDs and dates may appear in both DICOM and csv payloads, it is necessary to consistently mask the information – maintaining referential integrity of IDs and date shift amounts across the different payload types.
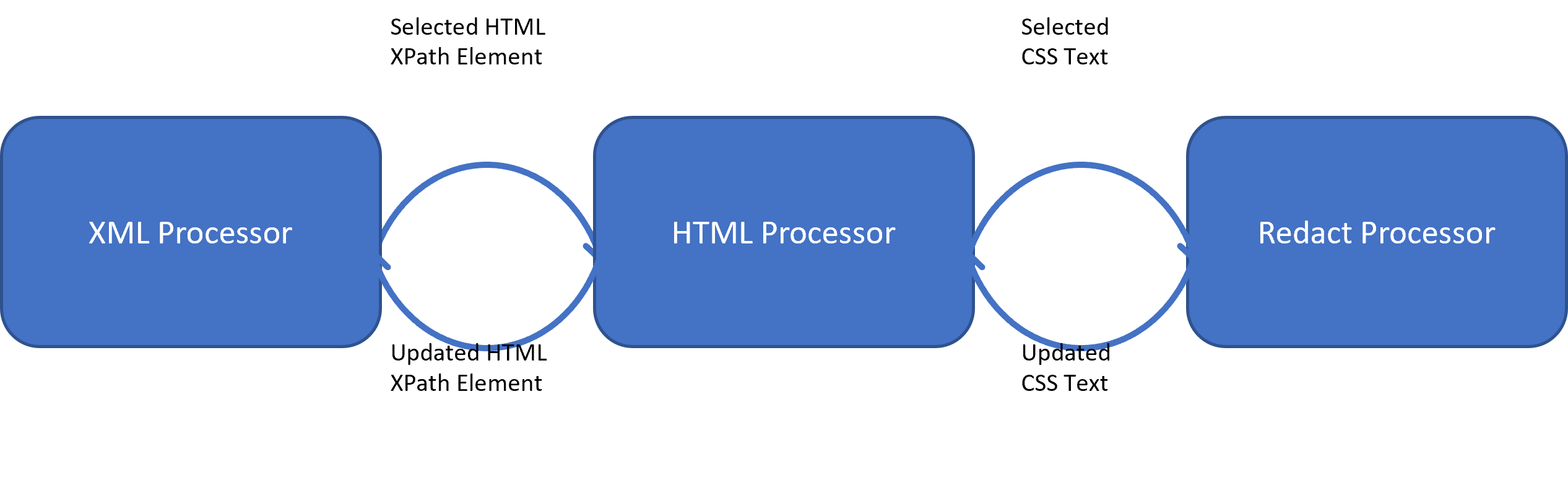
The masking tool follows this conceptual design:
- Processor – there are two types of processors that handle payloads:
- Inner Processor – These processors are payload specific and are responsible for parsing, selecting, extracting and updating data elements. An inner processor can be responsible for parsing an XML or pptx payload.
- Terminal Processor – These processors are responsible for the different types of operations such as format-preserving encryption, tokenization as well as operations on metadata. The input (and output) of this type of processor is always a string.
- Selector – a processor-specific abstraction that provides the ability to specify how to select a certain data element. For example, a selector can represent a json path identifying a json element.
Terminal processors are those that appear as leaves in the processing graphs. These processors can be roughly divided into (1) Metadata processors that modify metadata, and (2) Masking processors that modify data.
Metadata processors can perform any computation and store it for later use. For example, such a processor may save the content of column B (person name) for use when processing column E (email).
Masking processors are divided roughly into three types:
- Redact processors – replace the data with a predefined constant, e.g., “******”.
- Simple transformations – apply standard cryptographic operations such as hash (tokenize) or encrypt.
- Format preserving transformations – apply cryptographic transformations while maintaining the validity of the output, e.g., encrypting a credit card number to another fake – but valid – credit card number.
On top of these concepts, the tool enables building a data flow graph which realizes the processing flow. For example:
 Specific capabilities relevant to iToBoS
Specific capabilities relevant to iToBoS
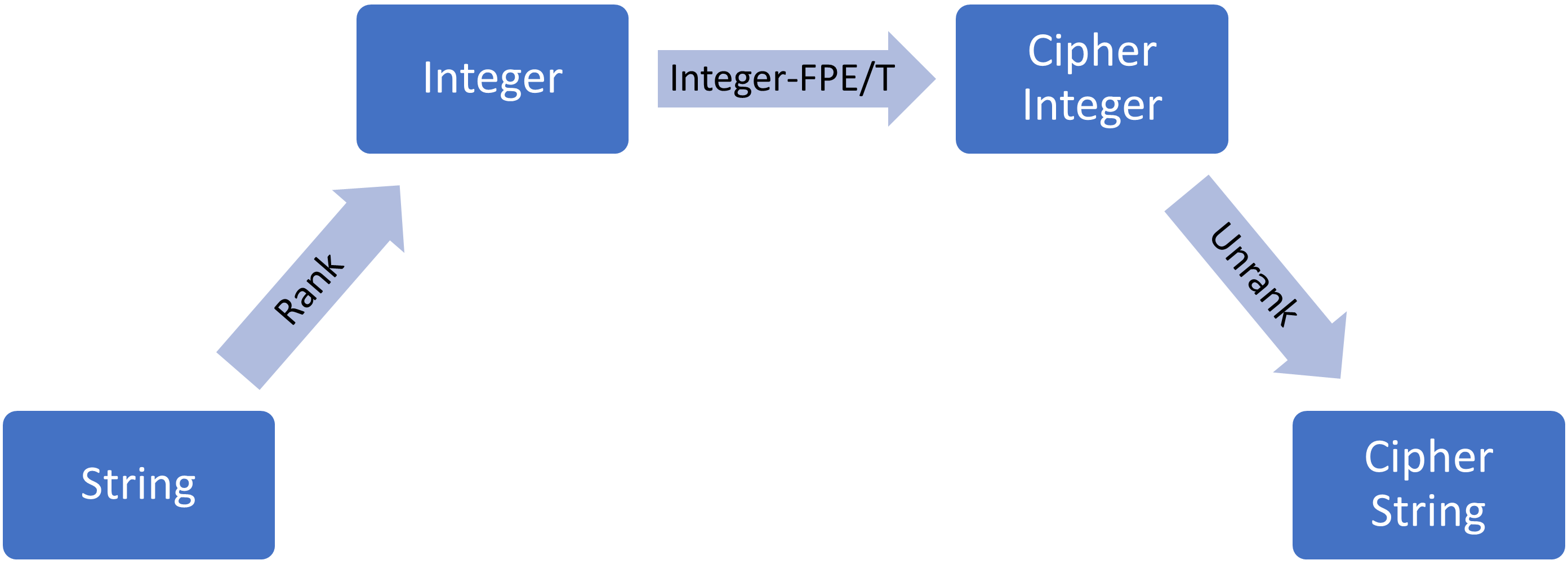
Rank and Cipher - In some use cases it may be required to mask a field such that the result maintains a valid data format. For example, if a credit card number should be masked to a valid, legal credit card number that will pass format validation in a given application. To achieve this there are several alternatives relying on different methodologies for string manipulation. Our tool’s format preserving encryption and tokenization masking methods build upon the Rank and Cipher method. In this method, the string is converted to an integer and the cypher operation is performed on the integers. This approach is both very efficient and allows us to generically support any user-defined data type.
The Rank and Cipher method has 3 steps:
- Rank – takes a valid string in the domain of the format and maps it to a unique number within the domain size (in a reversible manner). This operation is a simple mapping and does not provide any security guarantee.
- Apply a cryptographic operation (e.g., hash, encrypt) on the integer, such that the resulting integer is within the given domain.
- Unrank – is the reverse operation of ranking, i.e., mapping the integer back to a string.
Row level context - The CSV processor is one of the inner processors and is responsible for parsing and selecting elements from csv payloads. It supports selecting and processing cells based on their position (row and column) and does so sequentially. The processing order of the cells is dependent on the definition of the CSV processor.
Our implementation supports processing cells by rows rather than by columns. In essence, we process cells record by record. This ordering enables us to take advantage of record context and construct masking flows which can make use of one cell in a record to impact the processing of another cell in the same record. In particular, our masking configuration for IToBoS takes advantage of this behaviour by using the study id cell in the record as an input for computing the noise applied to the date cells of the same record.
AlterDateProcessor & AlterDateTimeProcessor - These processors are used to offset a date or timestamp by a given amount. The offset amount itself can be generated via a separate mechanism. Examples may include sampling noise from a distribution, or random noise fabrication within a range. This allows both separation of concerns as well as to set the offset amount within a certain context, such as per row (record). The latter mechanism can be useful for consistent time-series perturbation, as will be described in section Noise generation approach.
The AlterDateProcessor has two required parameters:
- The date pattern (String) - Any legal pattern supported by Java , e.g., dd/MM/yyyy.
- The date offset in days (Integer, may be positive or negative).
Similarly, the AlterDateTimeProcessor has three required parameters:
- The datetime pattern (String). Any legal pattern supported by Java, e.g., dd/MM/yyyy HH:mm:ss.
- The date offset in days (Integer, may be positive or negative).
- The time offset in seconds (Integer, may be positive or negative).
In order to support various date time formats and granularities, the AlterDateTimeProcessor supports strings that contain fractions of a second as well. Since the fractions of a second in some timestamps can have up to 6 digits, leaving the fraction would make the original value and the masked value easily correlated by the identical fraction of a second. To prevent this, the fraction is randomized as part of the datetime offset transformation.
Ranking of date formats (as part of the ‘rank and cipher’ approach) is done similarly to the MS Excel date representation, i.e., as an offset from a start or minimum date. The time rank is set by the offset from midnight. We leverage the format’s rank mechanism to perform the offset calculation, thus moving between days, months, and years is done transparently. The date is ranked to an integer, the offset is applied on the rank, and then we unrank the integer back to a date string. Thus, moving 10 days can change the month, year, or both.
There are several alternatives to perturb a value such as a date. The noise may be randomly generated, consistently generated given a seed (pivot), or selected from a given distribution such as bell curve (normal distribution), or a uniform distribution (i.e., equal probability for every value). In iToBoS we chose to generate consistent noise from a uniform distribution, given a pivot (seed). Since we want dates to be masked consistently for the same patient (i.e., approximately preserving the gaps between dates), we opted to use as the seed the study id field